

The short answer: NVMe over Fabrics (NVMe-oF) extends the near-local speed of NVMe flash across an Ethernet network so many servers can share one high-performance storage pool. Over Ethernet you have two practical transports. NVMe/TCP runs on any standard Ethernet with no special switch configuration and is the simplest path, effectively a faster successor to iSCSI. NVMe/RoCE uses RDMA to bypass the host CPU and OS kernel for the lowest latency, but it requires RDMA-capable NICs and a lossless fabric built with Data Center Bridging (PFC, ETS, ECN). Choose NVMe/TCP when simplicity, broad compatibility, and lower cost matter most. Choose NVMe/RoCE when microsecond-level latency and minimal CPU overhead are critical, and you can design and operate a lossless fabric. A well-architected network can carry both over the same fabric, letting you match transport to workload.
NVMe-oF Table of Contents
Typical Use Cases for NVMe-oF on Ethernet
Arista Networks: Enabling High-Performance NVMe-oF Deployments with Specific Features
Introduction: The Evolution from NVMe to NVMe-oF
The storage landscape has been revolutionized by Non-Volatile Memory Express (NVMe), a protocol designed specifically for flash-based storage. NVMe communicates directly with the system CPU via the high-speed PCIe (Peripheral Component Interconnect Express) bus, dramatically reducing latency and increasing performance compared to legacy protocols like SATA and SAS, which were designed for spinning disk drives. This direct path bypasses much of the traditional storage stack, unlocking the true potential of flash media.
However, the benefits of NVMe were initially confined to direct-attached storage (DAS), limiting its use in shared storage environments critical for enterprise applications. NVMe over Fabrics (NVMe-oF) was developed to extend these performance advantages across network fabrics, including Ethernet and Fibre Channel. This page focuses specifically on NVMe-oF over Ethernet, transforming how organizations access and share high-performance storage resources.
Core Benefits of NVMe-oF
Leveraging NVMe-oF allows businesses to disaggregate storage from compute while maintaining performance levels previously only achievable with DAS. The key benefits include:
Near-Local NVMe Performance: NVMe-oF is engineered to deliver exceptionally low latency, high Input/Output Operations Per Second (IOPS), and high throughput for networked SSDs, closely mirroring the performance of locally attached NVMe drives. This is achieved by maintaining the lightweight NVMe command set and queuing architecture across the fabric.
Improved Storage Efficiency and Scalability: By decoupling storage from compute, resources can be scaled independently, leading to better utilization and cost-effectiveness. Storage capacity and performance can be added to the network as needed, shared among many hosts.
Reduced CPU Overhead (especially with RDMA): Compared to older storage protocols like iSCSI, NVMe-oF can be significantly more efficient in its use of host CPU resources, particularly when using RDMA transports.
Future-Proof Architecture: As flash technology continues to advance, NVMe-oF provides a scalable and performant foundation to take advantage of future innovations in storage media.
NVMe-oF Transport Protocols over Ethernet: A Deep Dive
When deploying NVMe-oF over Ethernet, the choice of transport protocol is critical. Each has distinct characteristics, benefits, and requirements. The primary options are NVMe/TCP and NVMe/RoCE, with NVMe/iWARP being a less common consideration in current deployments.
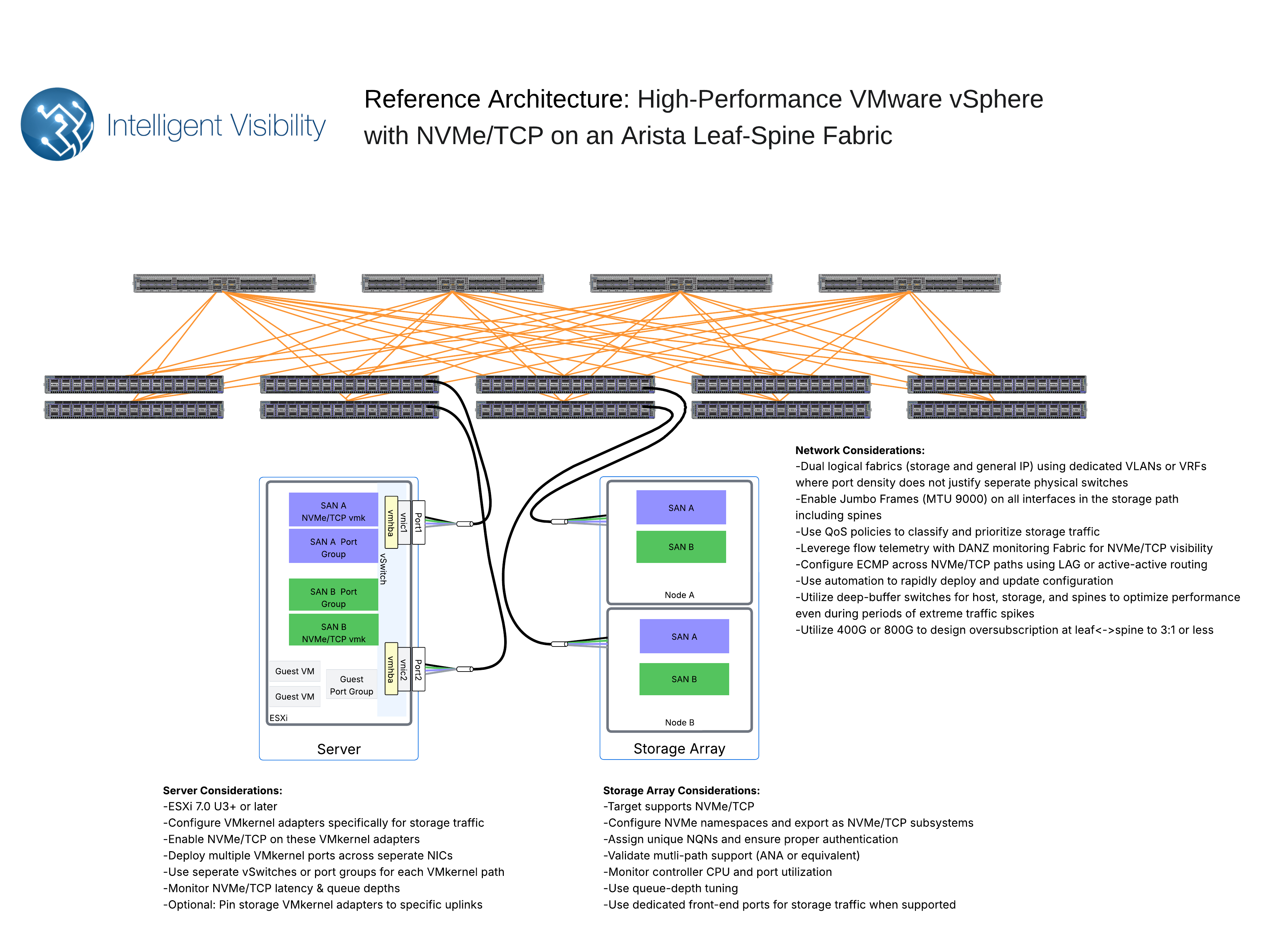
NVMe/TCP: Simplicity and Broad Compatibility
NVMe over TCP (NVMe/TCP) is designed to make NVMe-oF accessible and easy to deploy by leveraging the ubiquitous TCP/IP networking stack.
How NVMe/TCP Works: NVMe/TCP encapsulates NVMe commands and data within TCP packets. This allows NVMe-oF traffic to run over any standard Ethernet network infrastructure, including existing switches, routers, and NICs that support TCP/IP.
Benefits of NVMe/TCP:
Broad Compatibility: Works with virtually all existing Ethernet hardware and requires no special network configurations like Data Center Bridging (DCB) or RDMA.
Ease of Deployment: Simplified setup and management due to familiarity with TCP/IP networking. It's often seen as a natural, higher-performance successor to iSCSI.
Routability: Being built on TCP/IP, NVMe/TCP traffic is routable across complex network topologies and potentially even WANs (though latency considerations are paramount).
Lower Initial Cost: No need for specialized rNICs or DCB-capable switches can lead to lower upfront investment.
Considerations for NVMe/TCP:
CPU Overhead: The TCP/IP stack processing can consume host CPU cycles, potentially impacting application performance on the same host, especially at very high IOPS.
Balanced Latency View: While significantly lower than iSCSI and offering compelling performance for many applications, NVMe/TCP's inherent latency from the TCP stack is generally higher and may not match the ultra-low latency achievable with RDMA-based solutions like RoCE.
Mitigation Techniques:
TCP Offload Engines (TOEs): Some modern NICs offer TOE capabilities, offloading TCP processing from the host CPU to the NIC, which can reduce CPU utilization and improve performance.
Increased CPU Core Speeds and Counts: Faster CPUs can better handle the TCP/IP processing load.
Optimized Software Stacks: Efficient NVMe/TCP target and initiator implementations.
NVMe/RoCE: Ultra-Low Latency with RDMA
NVMe over RoCE (RDMA over Converged Ethernet) leverages Remote Direct Memory Access (RDMA) to achieve the lowest possible latency and high throughput by bypassing the host operating system's network stack.
How NVMe/RoCE Works: RoCE enables direct memory-to-memory transfers between hosts and storage targets across an Ethernet network. NVMe commands and data are passed directly to the application's memory buffers by the RDMA-capable NIC (rNIC), minimizing CPU involvement and eliminating kernel bypass overhead. RoCEv2, the most common version used, operates over UDP/IP, making it routable.
Benefits of NVMe/RoCE:
Ultra-Low Latency: By bypassing the kernel's network stack, RoCE can achieve latencies very close to that of local NVMe.
High Throughput: Efficient data transfers lead to excellent throughput.
Reduced CPU Utilization: Minimal CPU involvement in data movement frees up host resources for applications.
Critical Requirements & Deployment Nuances for NVMe/RoCE:
RDMA-capable NICs (rNICs): Both initiators (servers) and targets (storage arrays) must have rNICs that support RoCE. See our guide to selecting the right storage NIC (standard, TOE, rNIC, or DPU).
A Well-Configured, Lossless Ethernet Fabric: RoCE is highly sensitive to packet loss. Therefore, a "lossless" or near-lossless Ethernet network is absolutely crucial for reliable and optimal performance. Deploying RoCEv2 effectively means this fabric must be meticulously configured. This involves:
Data Center Bridging (DCB) technologies:
Priority-based Flow Control (PFC, IEEE 802.1Qbb): Prevents packet loss by sending pause frames for specific RoCE traffic classes when congestion occurs.
Enhanced Transmission Selection (ETS, IEEE 802.1Qaz): Allocates dedicated bandwidth to RoCE traffic classes.
Explicit Congestion Notification (ECN): Allows network devices to signal impending congestion without dropping packets, enabling endpoints to adjust.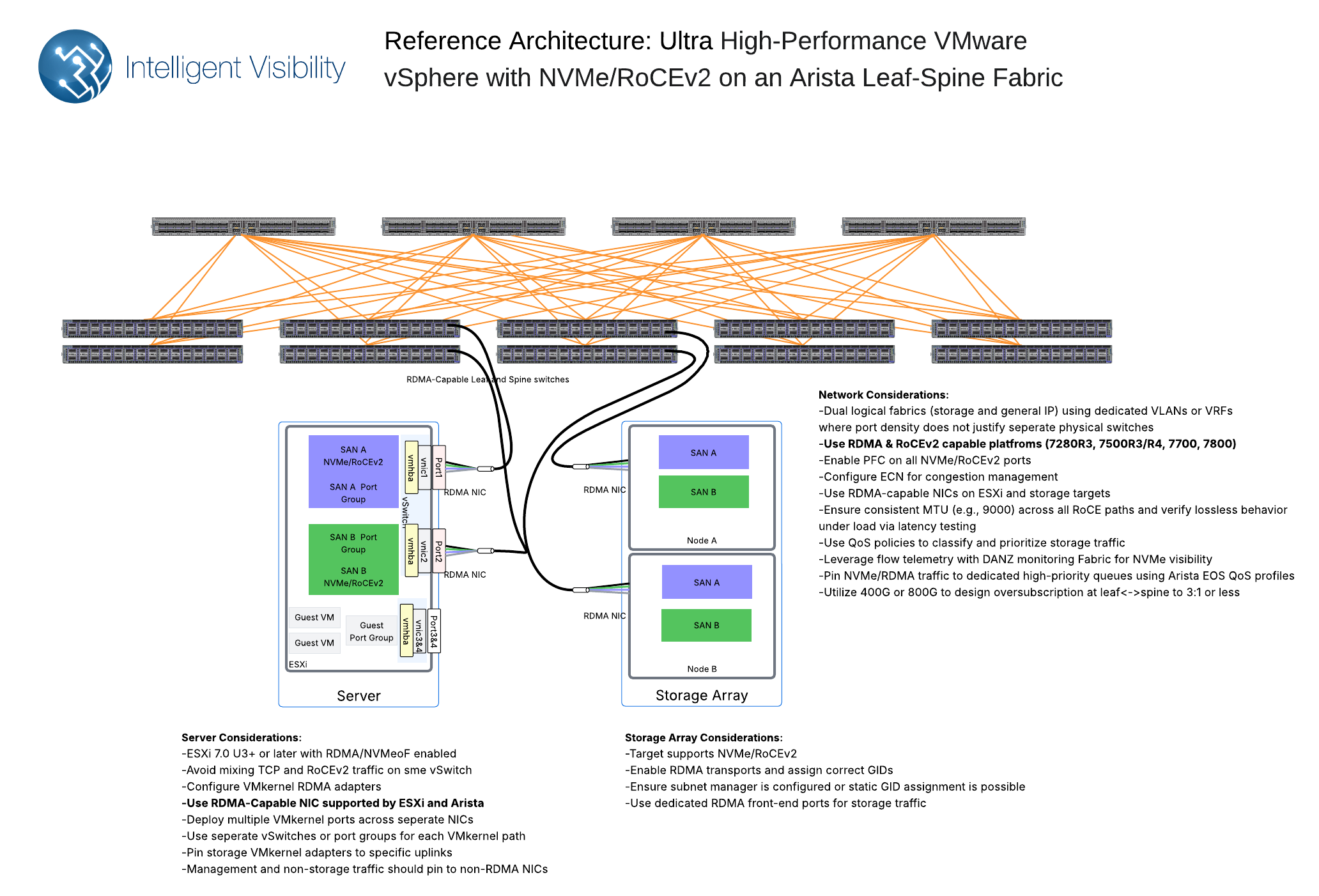
DCB-Capable Switches: Network switches must fully support and be expertly configured for these DCB features. This often involves additional complexity and potentially higher switch costs compared to standard Ethernet deployments. Incorrect configuration can lead to severe performance degradation or instability, negating the benefits of RoCE. For lossless RoCE fabric design and validation, IVI offers network design and consulting services.
NVMe/iWARP: An RDMA Option with Evolving Relevance
NVMe over iWARP (Internet Wide Area RDMA Protocol) is another RDMA-based transport that runs over TCP/IP, originally designed to offer RDMA benefits with broader compatibility than RoCE.
How NVMe/iWARP Works: iWARP encapsulates RDMA operations within TCP packets. TCP's inherent reliability and congestion control mechanisms handle packet ordering, retransmissions, and flow control.
Original Benefits of NVMe/iWARP:
RDMA Performance: Offered lower latency and CPU utilization compared to non-RDMA protocols by leveraging RDMA.
Standard Network Compatibility: Could operate over standard Ethernet networks without the strict lossless DCB fabric requirement of RoCE, as it relied on TCP/IP.
Current Adoption and Considerations:
While iWARP was an early RDMA transport option over Ethernet, its adoption in the NVMe-oF space has significantly declined in recent years.
The industry has largely gravitated towards RoCEv2 for deployments demanding the lowest possible latency (despite its fabric complexities) and NVMe/TCP for its simplicity, broad compatibility, and rapidly improving performance.
Factors contributing to iWARP's lesser adoption include a more limited ecosystem of supporting NICs compared to RoCE, and the fact that for many, the overhead of TCP (even with RDMA via iWARP) didn't always justify its selection over the increasingly optimized NVMe/TCP or the higher-performing RoCE in dedicated setups.
Therefore, while technically feasible, NVMe/iWARP is less commonly encountered in new NVMe-oF deployments as of 2025.
Is NVMe/RoCE faster than NVMe/TCP?
Choosing an NVMe-oF transport involves a trade-off between raw performance, infrastructure requirements, and cost. With iWARP's declining adoption, the primary comparison is often between NVMe/TCP and NVMe/RoCE.
Latency:
NVMe/RoCE: Typically offers the lowest latency (often in the sub-10 to tens of microseconds range added to the base NVMe device latency) in well-configured, lossless DCB environments.
NVMe/TCP: Latency is higher than RoCE (can add tens to over a hundred microseconds), but still significantly better than traditional iSCSI. It is important to acknowledge that while NVMe/TCP provides compelling performance and ease of deployment, it may not match the ultra-low latency of RDMA-based solutions like RoCE, which is critical for some applications.
IOPS and Throughput:
NVMe/RoCE: Generally achieves higher IOPS and throughput compared to NVMe/TCP, especially as workloads scale, due to lower CPU overhead and a more efficient data path.
NVMe/TCP: Can deliver impressive IOPS and throughput, often saturating slower NVMe devices or network links, but may require more host CPU resources to achieve this.
CPU Utilization:
NVMe/RoCE: Significantly lower host CPU utilization due to kernel bypass and direct data placement by rNICs. This is a major advantage for environments where host CPU cycles are a premium.
NVMe/TCP: Higher CPU utilization due to TCP/IP stack processing. This can become a bottleneck for achieving maximum IOPS on very fast storage or with many LUNs.
Realistic Expectations: Marketing materials often showcase "hero numbers" achieved in perfect lab conditions. Real-world performance will depend on:
The specific capabilities of the NVMe SSDs.
The speed and quality of the network infrastructure (NICs, switches, cabling) and its configuration.
The efficiency of the initiator and target software stacks.
The nature of the application workload (e.g., read/write mix, I/O size, randomness).
Proper end-to-end configuration and tuning – especially critical for RoCE.
While RoCE generally leads in raw performance metrics, NVMe/TCP often provides excellent performance with greater simplicity and lower infrastructure cost, making it a very viable and increasingly popular option.
Deployment Considerations: Choosing Your Path
Beyond raw performance, several factors influence the choice of NVMe-oF transport:
Network Infrastructure Requirements:
NVMe/TCP: Standard Ethernet switches and NICs (10GbE, 25GbE, 100GbE or faster). No special features required beyond sufficient bandwidth. Learn what to prioritize when choosing switches for storage traffic.
NVMe/RoCE: Requires DCB-capable switches and a meticulously configured lossless fabric. This demands expertise in DCB and potentially more expensive switches, adding to deployment complexity and cost.
Operating System and Driver Support:
Both NVMe/TCP and NVMe/RoCE generally have good support in modern enterprise Linux distributions and VMware vSphere. Windows Server support is also maturing.
Ensure compatibility between the chosen NICs, their drivers, the OS, and the storage array's NVMe-oF implementation.
Hardware Costs and TCO:
NICs: Standard NICs for NVMe/TCP are the most cost-effective. rNICs for RoCE are more expensive.
Switches: Standard Ethernet switches for NVMe/TCP are less expensive than the DCB-capable switches typically required for robust RoCE deployments.
Overall TCO: NVMe/TCP might have lower CapEx. RoCE's higher CapEx for rNICs and specialized switches might be offset by better server efficiency for extremely demanding workloads, but the management overhead of the lossless fabric must also be factored in.
Management Complexity:
NVMe/TCP: Simplest to deploy and manage due to familiarity with standard IP networking.
NVMe/RoCE: Most complex due to the strict requirement for a well-configured lossless DCB fabric. Misconfigurations can lead to severe performance degradation. This complexity is a significant factor in deployment decisions.
Should I choose NVMe/TCP or NVMe/RoCE?
The decision between NVMe/TCP and NVMe/RoCE is a significant architectural one:
Choose NVMe/TCP if:
Simplicity, ease of deployment, and broad compatibility are paramount.
You need to leverage existing standard Ethernet infrastructure without extensive reconfiguration.
Budget for specialized NICs and DCB-capable switches is constrained.
The excellent performance improvement over iSCSI is sufficient, and achieving the absolute lowest possible microsecond-level latency (as offered by RoCE) isn't the overriding priority for all workloads.
It is important to note that a well-architected network, with proper platform selections, can run both NVMe/TCP and NVMe/RoCE over the same fabric, allowing you to balance investment with performance on a workload-by-workload basis
Choose NVMe/RoCE if:
Achieving the absolute lowest latency and highest IOPS with minimal CPU impact is critical for specific, highly sensitive applications.
You have the budget, expertise, and operational commitment to design, implement, and meticulously manage a lossless DCB Ethernet fabric.
Workloads are extremely performance-sensitive (e.g., high-frequency trading, certain real-time databases, demanding HPC).
The choice impacts Total Cost of Ownership (TCO), management overhead, and infrastructure complexity. NVMe/RoCE's demands for rNICs and expertly configured DCB-enabled switches are significant considerations against its raw performance potential.
Typical Use Cases for NVMe-oF on Ethernet
NVMe-oF is ideal for applications that demand high IOPS, high throughput, and low latency from shared storage. Common use cases include:
High-Performance Databases: OLTP, OLAP, NoSQL databases.
Real-Time Analytics: Applications processing large datasets.
Artificial Intelligence (AI) and Machine Learning (ML) Workloads: Training and inference phases.
High-Performance Computing (HPC): Scientific research and simulations.
Cloud Storage Solutions: High-performance block storage for VMs and containers.
Virtual Desktop Infrastructure (VDI) at Scale.
Media and Entertainment: High-resolution video editing.
Arista Networks: Enabling High-Performance NVMe-oF Deployments with Specific Features
Modern Ethernet fabrics are crucial for successful NVMe-oF deployments, especially for latency-sensitive RDMA transports like RoCEv2. Arista Networks provides robust switching platforms and software features well-suited for these demanding environments.
Support for NVMe/TCP: Arista switches deliver the high-bandwidth, low-latency foundation essential for efficient NVMe/TCP traffic, integrating seamlessly into standard IP storage networks. Their consistent low latency is beneficial even for TCP-based storage.
Robust NVMe/RoCEv2 Enablement: Arista's platforms are engineered to support the stringent requirements of RoCEv2:
Comprehensive Data Center Bridging (DCB) Implementation: Arista EOS provides full support for PFC (Priority-based Flow Control), ETS (Enhanced Transmission Selection), and ECN (Explicit Congestion Notification). These are fundamental for creating the lossless Ethernet environments necessary for optimal RoCEv2 performance. PFC prevents packet drops for RoCE traffic, ETS guarantees bandwidth, and ECN helps manage congestion proactively.
Deep Buffer Architectures: Many Arista switches, particularly in the R-series (like the 7280R3 series), feature ultra-deep packet buffers. These large buffers are critical for absorbing traffic bursts (microbursts) common in storage I/O, such as incast scenarios from multiple servers accessing storage simultaneously. This helps prevent packet loss during periods of congestion, further ensuring smooth and predictable performance for RoCEv2 and other storage traffic.
Low Latency Design: Arista switches are engineered for low and consistent cut-through latency, minimizing transit delay for storage traffic.
Observability and Automation: Tools like Arista CloudVision® provide network-wide visibility into performance metrics crucial for storage, including buffer utilization, latency, and congestion. This aids in monitoring, troubleshooting, and optimizing NVMe-oF traffic flows, particularly in complex RoCEv2 deployments. Automation features can simplify the configuration and management of DCB settings across the fabric.
Arista's commitment to open standards, combined with these specific hardware and software capabilities, directly supports the "Future-Proof & Open" and "Performance & Low Latency" themes critical for modern Ethernet storage networks, especially those leveraging NVMe/RoCEv2.
Conclusion: Future-Proofing Your Storage with NVMe-oF on Ethernet
NVMe-oF over Ethernet provides a powerful and flexible way to extend the remarkable performance of NVMe SSDs across the network. By understanding the distinct characteristics, benefits, and trade-offs of NVMe/TCP and NVMe/RoCE, organizations can make informed architectural decisions. The choice will depend on specific performance requirements, existing infrastructure, budget, and operational capabilities, keeping in mind the declining relevance of iWARP in this space.
Whether opting for the widespread compatibility and ease of NVMe/TCP or the ultra-low latency of a well-architected NVMe/RoCE deployment, NVMe-oF on Ethernet is a cornerstone technology for building next-generation data centers. It offers a compelling path to enhanced performance, scalability, and efficiency for the most demanding applications and workloads.